|

我从博客的读者中收到这个显然很简单的问题:在STM32中我怎么能延迟几个微秒的时间?也就是说,如何精确地测量STM32的微秒? 答案是:有几种方法可以做到这一点,但某些方法更准确和另外一些在不同的MCU和时钟配置时更通用。 让我们以STM32F4系列中的一员为例:STM32F401RE,STM32Nucleo-F401RE板的MCU。该板使用内部RC时钟能够运行到84MHz。这意味着每过1μs,时钟周期运行84次。因此,我们需要一种方法来计算84个时钟周期来代表过去的1μs(我假设你能接受1%精度的内部RC时钟)。
有时经常会发现这样的代码: - void delay1US() {
- #define CLOCK_CYCLES_PER_INSTRUCTION X
- #define CLOCK_FREQ Y //IN MHZ (e.g. 16 for 16 MHZ)
- volatile int cycleCount = CLOCK_FREQ / CLOCK_CYCLE_PER_INSTRUCTION;
- while (cycleCount--);
- // 1uS is elapsed :-)
- // Sure?
- // :-/
- }
但是如何建立计算while(cycleCount--)指令的一步需要多少个时钟周?不幸的是,并不是很容易地给你一个答案。假设CycleCount计数值等于1。做一些测试(稍后我将解释我是如何做到这些),编译器优化被禁用(GCC的option -O0),我们可以看到,在这种情况下,整个Ç指令需要执行24个周期。这怎么可能呢?你必须弄清楚,如果我们反汇编固件的二进制文件,我们的C语句会展开为几个汇编指令,我们可以看到: - ...
- while(counter--);
- 800183e: f89d 3003 ldrb.w r3, [sp, #3]
- 8001842: b2db uxtb r3, r3
- 8001844: 1e5a subs r2, r3, #1
- 8001846: b2d2 uxtb r2, r2
- 8001848: f88d 2003 strb.w r2, [sp, #3]
- 800184c: 2b00 cmp r3, #0
- 800184e: d1f6 bne.n 800183e <main+0x3e>
此外,时间等待的另一个来源是从MCU内部闪存的获取。因此,该指令有24个周期的“基本花费”。如果CycleCount计数值等于2需要多少个周期?在这种情况下,在MCU需要33个周期,即附加9个周期。这意味着,如果我们想延迟84个周期,那么CycleCount计数值必须等于(84-24)/9,约等于7。因此,我们可以在使用更一般的方式来写我们的延时函数: - void delayUS(uint32_t us) {
- volatile uint32_t counter = 7*us;
- while(counter--);
- }
使用以下代码测试这个功能: - while(1) {
- delayUS(1);
- GPIOA->ODR = 0x0;
- delayUS(1);
- GPIOA->ODR = 0x20;
- }
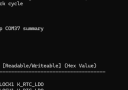
我们可以使用一个合适的示波器,并且连接到配置为GPIO_SPEED_HIGH的GPIO,检查是否是我们所期望的:

使用这种方式来延时1μs是否始终能保持不变?答案是否定的。首先,它只有当这个特定的MCU(STM32F401RE)工作在全速模式(84Mhz)时工作得很好。如果你决定使用不同的时钟速度,你需要重新安排它做试验。其次,它受编译器优化影响。 现在,我们使能GCC优化为“size”(-Os)。我们得到什么样的结果?在这种情况下,delayUS()函数只消耗72个CPU周期,约为850ns。示波器证实了这一点:

如果我们使能最大优化speed (-O3)会发生什么呢?在这种情况下,我们只消耗64个CPU周期,也就是说我们的delayUS()函数只持续约750ns,示波器证实了这点:

但是,这个问题可以通过使用特定的GCC编译指令来解决: - #pragma GCC push_options
- #pragma GCC optimize ("O0")
- void delayUS(uint32_t us) {
- volatile uint32_t counter = 7*us;
- while(counter--);
- }
- #pragma GCC pop_options
话虽如此,但事实上,如果我们想用一个较低的CPU频率,或者我们想将代码放到另一个不同的MCU,我们需要再次重新进行测试。 那么,如果我们改变了硬件设置,怎样才能获得精确1μs的延迟,并且不用做测试?答案是:我们需要一个硬件定时器。我们有几种选择。 第一种方法来自先前的测试。我是如何测量CPU周期的? Cortex-M处理器可以有一个可选的调试单元,提供了观察点、数据跟踪和处理器的系统性能。这个单元的一个寄存器是CYCCNT,该寄存器计算CPU执行的周期数。因此,我们可以使用STM32的特殊单元来计算指令执行期间由MCU执行的循环次数。 - uint32_t cycles = 0;
- /* DWT struct is defined inside the core_cm4.h file */
- DWT->CTRL |= 1 ; // enable the counter
- DWT->CYCCNT = 0; // reset the counter
- delayUS(1);
- cycles = DWT->CYCCNT;
- cycles--; /* We subtract the cycle used to transfer
- CYCCNT content to cycles variable */
使用DWT我们可以建立这样一个更通用的delayUS()函数: - #pragma GCC push_options
- #pragma GCC optimize ("O3")
- void delayUS_DWT(uint32_t us) {
- volatile uint32_t cycles = (SystemCoreClock/1000000L)*us;
- volatile uint32_t start = DWT->CYCCNT;
- do {
- } while(DWT->CYCCNT - start < cycles);
- }
- #pragma GCC pop_options
这个函数有多精确呢?如果您比较关心1μs的最佳分辨率,那么这个函数不是最好的,如示波器所示。

当设置较高的编译器优化级别将会获得最佳的性能。正如你所看到的,对于为1μs的延时该函数提供了大约1.22μs的延迟(慢22%)。但是,如果我们想延时10μs,我们得到了10.5μs的延迟(慢5%),这更接近于我们想要的。

从100μS的延迟开始误差完全可以忽略不计。 为什么这个函数并非如此精确?要理解为什么这个函数比另外一个不太精确,你需要明白,自函数开始时(while条件),我们使用的是一系列指令来检查消耗了多少个周期。这些指令花费的CPU周期不仅用于更新内部CPU寄存器包括CYCCNT的内容,而且包括做对比和分支。但是,这个函数的优势是,它可以自动检测CPU速度,而且它能更好的工作,特别是如果我们正在较快的处理器。 其它解决方案可以使用硬件定时器,像TIMX和SYSTICK定时器来实现。不过,可以通过类似delayUS_DWT()函数来获得性能。 如果你想完全控制编译器的优化,可以利用此宏完全用汇编语言编写达到最好的1μs的延迟: - #define delayUS_ASM(us) do {\
- asm volatile ( "MOV R0,%[loops]\n\t"\
- "1: \n\t"\
- "SUB R0, #1\n\t"\
- "CMP R0, #0\n\t"\
- "BNE 1b \n\t" : : [loops] "r" (16*us) : "memory"\
- );\
- } while(0)
这是最优化的方式来写while(counter--)函数。通过使用示波器做测试,我发现当MCU在84MHZ执行这个循环16次可以获得1μs的延迟。但是,如果你的处理器速度较低,这个宏需要重新安排,记住,作为一个宏,每次使用它的时候它会“扩大”,引起固件大小的增加。 |